Operate Like Engineers: SRE for Distributed Platforms
by Selwyn Davidraj Posted on September 28, 2025
This blog explores how distributed architecture is reshaping traditional operations by driving the adoption of Site Reliability Engineering (SRE) practices.
Brief Summary
Distributed architecture refers to a system design where components (services, databases, etc.) run on multiple interconnected nodes instead of a single server. This approach (exemplified by microservices, distributed databases, and service meshes) has become essential in modern retail and e-commerce applications to meet high scalability, performance, and reliability demands. However, distributing an application into many microservices and data stores introduces significant operational challenges – from increased system complexity and data consistency issues to difficulties in monitoring (observability) and failure management. These complexities are driving a transformation in traditional IT operations towards Site Reliability Engineering (SRE), which treats operations as a software problem. SRE principles emphasize automation, observability, and resilience to thrive in this complexity. In practice, SRE teams in e-commerce must tackle challenges like service sprawl, cross-service communication failures, and fragmented monitoring by implementing robust solutions (such as distributed tracing, centralized logging, fault-tolerance patterns, and SLO-based management). This blog provides a detailed look at what distributed architecture entails, why it necessitates an SRE approach, the key challenges it brings (especially for retail systems), and a strategic guide (including a challenge-solution table) for SRE teams to navigate and overcome these challenges.
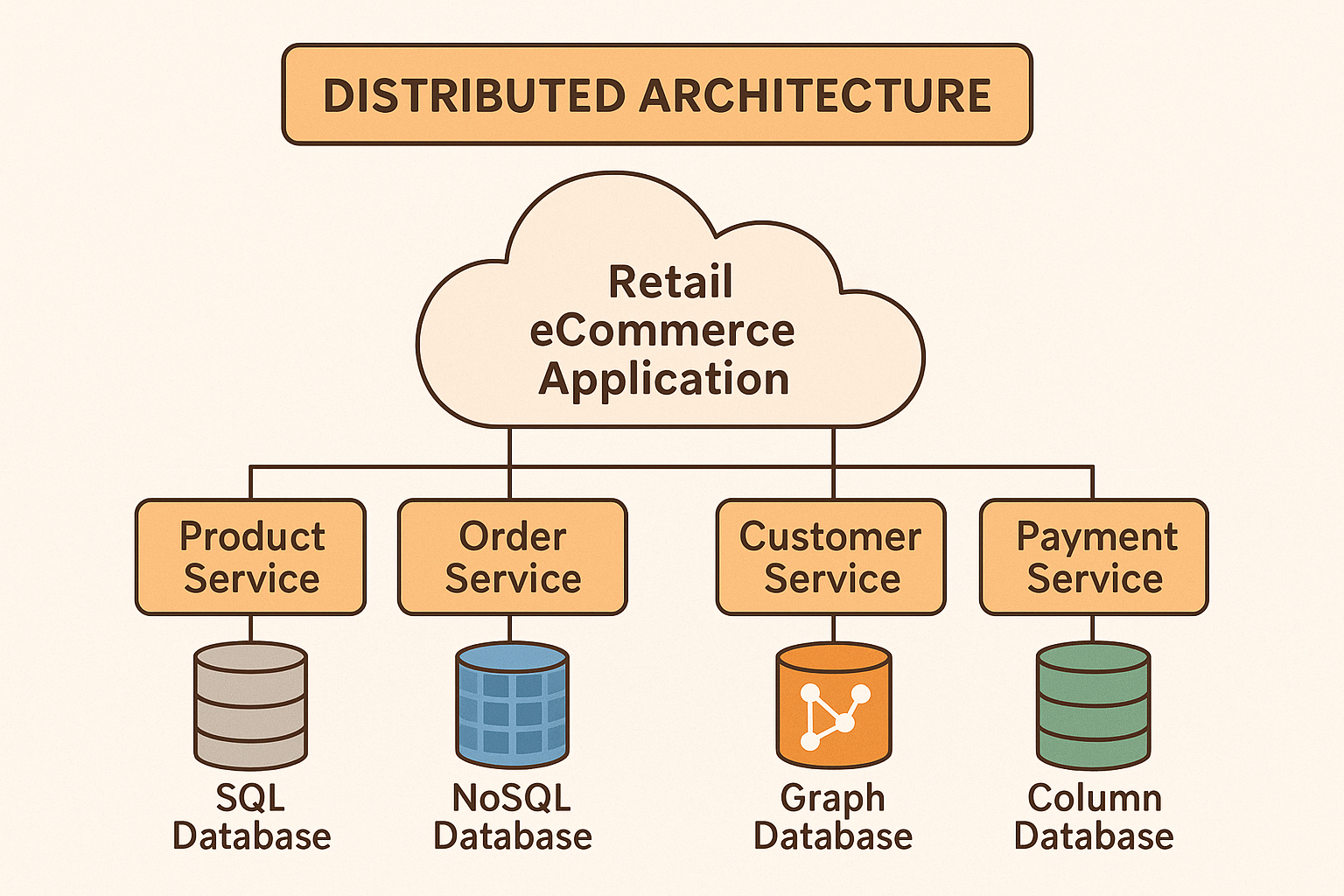
Challenges of Adopting Distributed Architecture (Retail & E-commerce Focus)
In the world of retail and e-commerce, scaling to millions of customers while staying always-on is no longer optional — it’s survival. The backbone of this scale is distributed architecture: microservices, distributed databases, and service meshes working together to deliver experiences like one-click checkout, personalized recommendations, and real-time inventory.
While distributed architecture brings clear benefits (scalability, flexibility, fault isolation), it also introduces unique challenges that must be addressed. In retail and e-commerce environments, these challenges are pronounced due to high transaction volumes, rapid feature iterations, and customer expectations for 24/7 uptime. Below are some of the key challenges an organization faces when moving to a microservices-based distributed system, and subsequently how SRE teams can address them. (Both technical and organizational challenges are considered, as success requires handling both the engineering complexities and the cultural shifts.)
| Challenge | SRE Perspective: Strategies & Solutions |
|---|---|
| Service Sprawl & Complexity – Many independent services and tech stacks to manage; hard to track dependencies | Inventory and map the ecosystem: Implement a service catalog or dependency map to track all services and their owners. Use container orchestration (e.g. Kubernetes) to standardize deployments, and infrastructure-as-code to manage configurations centrally. SREs also enforce coding standards and automation for all services to reduce complexity (e.g. uniform logging formats, consistent health check endpoints). Platform teams may provide tooling to hide some complexity and enable developer self-service while maintaining reliability standards |
| Observability Gaps – Limited visibility into system behavior; difficult to trace transactions across services and data stores | Build a unified observability stack: Establish the “three pillars” of observability (logs, metrics, traces) for all services. SREs should deploy centralized log aggregation and monitoring systems (e.g. ELK stack for logs, Prometheus/Grafana for metrics) and implement distributed tracing (using OpenTelemetry, Jaeger, etc.) so that any transaction can be followed end-to-end. Instrument code and use correlation IDs to tie together logs and traces from different services. Also leverage service mesh telemetry for standard metrics (like request rates, latencies) across microservices. Regularly create dashboards and alerts based on SLOs (e.g. error rate, response time) to detect issues early. If in-house integration is too complex, consider managed observability platforms that provide full end-to-end tracing with minimal overhead |
| Inter-Service Communication & Latency – Network overhead, unpredictable latency, and call failures when services talk to each other | Engineer for resilience and performance: Implement timeouts, retries, and circuit breakers on service calls (often via a service mesh or client libraries) to prevent cascading failures. SREs can set SLIs/SLOs for service latency and monitor for any unusual spikes in latency between services. Use load balancing and throttling to ensure no single service is overloaded by requests. For performance, optimize communication patterns – e.g. prefer asynchronous messaging (queues, events) where possible to decouple services and reduce user-facing latency. In e-commerce, this might mean using events to update inventory or send order confirmations instead of making the customer wait for every downstream update to complete. SRE teams should also perform chaos testing and latency injection to see how the system behaves under network delays, ensuring the overall application remains within acceptable performance limits. |
| Data Consistency & Distributed Transactions – Keeping data in sync across multiple databases / services; risk of anomalies without a single source of truth | Embrace eventual consistency with safeguards: Design the system with clear data ownership – each microservice owns specific data to avoid frequent cross-service transactions. Where cross-service consistency is needed, use saga patterns or workflows to coordinate updates in a fail-safe manner. SREs can help implement idempotency and retry logic for events so that if a step fails, it can be retried without duplicating data. Use change data capture and events to propagate changes reliably (e.g. an Order service emits an event that Inventory service listens to, updating stock). Also, deploy monitoring on data integrity – for example, periodic checks or alerts if data between services diverges (like an order status in service A not matching payment status in service B). In retail, keeping an eye on inventory synchronization across channels is critical, so SRE might create automated scripts to reconcile stock levels between microservices daily. |
| Fault Tolerance & Partial Failures – Services can fail independently; need to prevent one failure from cascading and causing system-wide outages | Design for graceful degradation: Apply redundancy at every level – multiple instances of each service (across zones/regions), and fallback logic if a service is unavailable. SREs should ensure that critical user flows have fallback paths (e.g. if the recommendation service is down, the site still functions minus recommendations). Implement circuit breakers so that if a service is unresponsive, dependent services stop waiting on it and use defaults or cached data. Utilize health checks and auto-healing – orchestrators like Kubernetes can restart unhealthy containers automatically, and auto-scaling can kick in to add capacity if instances fail. SRE teams also use fault injection testing (chaos engineering) to simulate service outages regularly (for instance, kill pods of a service randomly) to verify the system can tolerate failures without breaching SLOs. Over time, this builds confidence that no single failure will take down the entire e-commerce platform. |
| Security & Compliance – More services = more endpoints and data stores to secure; ensuring consistent security and meeting compliance across a distributed system | Automate and standardize security measures: Use a service mesh or API gateway to enforce security centrally – e.g. mutual TLS for all service-to-service communication, and authentication/authorization middleware for each request. SRE and security teams can collaborate to embed security checks into the CI/CD pipeline (scanning container images, checking dependencies for vulnerabilities) so that each microservice follows security best practices. Maintain a zero-trust network stance: even inside the cluster, treat connections as potentially untrusted. For compliance (PCI, GDPR), use data encryption at rest and in transit, and keep logs of access to sensitive services. SRE can help by ensuring audit logging is enabled on all services and by managing secrets via secure stores (so credentials aren’t hard-coded). Regular chaos security engineering drills (simulating attacks or misconfigurations) can be performed to test the system’s security resilience. The goal is to ensure the distributed architecture does not compromise on security compared to a centralized one. |
| Operational Tooling & Skills Gap – Need for new tools (containers, CI/CD, monitoring) and upskilling the team; risk of fragmented toolsets and inconsistent practices | Invest in platforms and training: SRE leadership should push for an internal developer platform or standardized tooling that makes it easy for development teams to do the right thing (e.g. templates for new microservices that include default observability, security, build pipelines). This reduces variation and ensures every service meets baseline reliability standards. Provide comprehensive training programs to upskill traditional ops and dev team members in SRE practices, cloud infrastructure, and automation. Pair new SREs with seasoned engineers and rotate folks through SRE roles to spread knowledge. To combat tooling fragmentation, choose a single observability platform or integrate tools so that everyone uses the same dashboards and alerting systems. The SRE team can maintain documentation and runbooks that codify best practices for deploying and operating microservices, serving as a guide for the rest of the organization. Over time, cultivate a culture where developers think about reliability and operations from day one (sometimes called “You build it, you run it”), with SREs as facilitators and subject-matter experts rather than firefighters. |
| DevOps Culture & Process Change – Shifting from siloed ops to a DevOps/SRE model; resistance to change and unclear responsibilities during the transition | Foster a reliability-focused culture: Leadership should clearly communicate the vision for SRE and why it’s needed (especially in context of modernizing a retail platform). Introduce blameless post-mortems and celebrate learning from failures to encourage openness. Redefine roles such that developers and SREs have shared ownership of reliability – for example, set up an on-call rotation that developers participate in for their services, supported by SREs, to break down “us vs them” walls. Use SLOs as common goals that product, dev, and SRE teams all care about (e.g. 99.9% uptime on checkout service). SREs can run game days (reliability drills) with cross-team participation to build trust and awareness. Also, start with small wins: maybe embed an SRE with a particular service team to improve reliability there, then use that success story to drive broader adoption. By addressing fears (e.g. ops folks worried about coding – give them training and time to learn) and showing the benefits (faster incident resolution, happier customers), the organization can gradually transform. Overcoming cultural inertia is challenging, but it’s crucial because without a supportive culture, the best tools and architectures will fall short in practice. |
Strategic Guide for SRE Teams to Overcome Distributed Architecture Challenges
1. Establish Robust Observability from Day 1:
“You can’t manage what you can’t see.” Invest early in a comprehensive observability framework. This means instrumenting your microservices for metrics (throughput, latency, error rates), implementing centralized logging, and deploying distributed tracing. For example, use OpenTelemetry libraries in all services so that traces propagate with each user request. Build dashboards that aggregate the Four Golden Signals (latency, traffic, errors, saturation) for each service. In a retail scenario, have a live dashboard for key user flows (e.g. from product view to checkout) that shows where latency is spent across services. Set up alerts on SLO violations (like if payment success rate drops below 99.9% over 5 minutes, trigger an immediate page). Effective observability will drastically reduce time to detect and diagnose issues in distributed systems.
2. Define SLOs and Error Budgets Aligned with Business Goals:
Work with business and product stakeholders to translate customer expectations into concrete reliability targets. For instance, if “fast checkout” is a selling point, define an SLO like “95% of checkout API calls complete within 2 seconds.” Use these SLOs to guide decision-making – for example, if error budgets are getting exhausted (too many failures breaching the SLO), SRE can call for a slowdown in feature releases to focus on reliability improvements. In e-commerce, also consider seasonality – you might tighten SLOs or error budget policies before major sales events when reliability is most crucial. By quantifying reliability, SRE provides a vital data-driven link between operations and business outcomes, ensuring everyone knows what “reliable” means in measurable terms.
3. Implement Resilience Patterns and Chaos Engineering:
Don’t assume services will only fail in isolation – design and test for the worst. Introduce resilience patterns systematically: timeouts on external calls, retry with backoff for transient errors, circuit breakers to cut off truly failing services, bulkheads to isolate resource usage, and fallbacks for essential user-facing features. A service mesh can enforce some of these policies uniformly (e.g. Envoy proxies can enforce timeouts/circuit breaking without code changes). Complement this by running chaos engineering experiments in staging (and eventually in production during off-hours or for small percentages of traffic): deliberately shut down instances, break network connections, or make a dependency return errors. Monitor how the system responds – do users still get a reasonable experience? Does the system self-heal? These drills will expose weaknesses that you can fix proactively. For example, you might discover that if the recommendation service is down, it causes threads to pile up on the product page service – leading you to add a fallback to skip recommendations when it’s unavailable. Over time, this practice hardens the e-commerce platform against real-world incidents.
4. Leverage Automation and Orchestration Tools:
In a distributed architecture, manual configuration or releases can’t keep up. Use Infrastructure as Code (Terraform, CloudFormation, etc.) for provisioning so that environments are reproducible and scalable. Embrace container orchestration (Kubernetes or managed cloud services) to handle deployment, scaling, and recovery of services automatically. Set up continuous integration/continuous deployment (CI/CD) pipelines such that tests are run and deployments are triggered for each microservice in a controlled manner. Automate canary or blue-green deployments so new versions can be rolled out with minimal risk. For operations, automate routine tasks (script automatable runbook actions, e.g. a script to archive old logs or to reset a stuck message queue). The aim is to minimize human toil and error in managing the system. This not only improves efficiency but also consistency – automation ensures every service and environment undergoes the same validated steps. In peak retail season, automation allows you to confidently scale out services or deploy optimizations without scrambling manually.
5. Build an Integrated Platform for Developers (DevOps Enablement):
Successful SRE efforts often involve enabling development teams to move fast without breaking things. To do this, build an internal platform or toolkit that handles common concerns for microservices. For example, provide a standardized service template that includes logging/tracing setup, health check endpoints, and CI/CD config out-of-the-box. Offer self-service tools for developers to deploy or rollback their services with a button click (with SRE guarding the pipelines). Encourage using common libraries for things like database access or messaging, so that instrumentation and error handling are uniform. This reduces the cognitive load on developers and encourages best practices. It also frees SREs from being gatekeepers for every little change – instead they focus on improving the platform and reliability features. Over time, this platform approach yields more reliable systems because every service is built on proven patterns, and it reduces the variability that often causes rare bugs. Essentially, SRE works hand-in-hand with a Platform Engineering mindset to make the “paved road” (the easy way) also the right way for reliability.
6. Prioritize Capacity Planning and Performance Testing:
Retail and e-commerce systems experience wild swings in traffic (think Black Friday or holiday sales). A distributed architecture can scale, but only if you’ve done the homework to ensure capacity. SREs should institute regular capacity planning exercises – analyze growth trends, run load tests, and determine how much headroom is available for each critical service. Simulate peak loads in staging environments; test things like 2x or 5x your normal traffic to see where bottlenecks emerge. Ensure auto-scaling rules are in place and tested – for instance, verify that when web traffic surges, new application instances come online and database replicas can handle the load. Also plan for dependency capacity: it’s common for one microservice to scale out and accidentally overload a downstream service that wasn’t scaled. SRE should coordinate end-to-end performance tests to catch such scenarios. By being proactive, come the big sale day, the team can be confident that the system can handle the influx (and if certain limits exist, those are known and communicated, with mitigation plans ready).
7. Continuous Improvement via Blameless Postmortems (BPM):
Despite best efforts, incidents will happen. What’s critical in an SRE culture is to learn from every failure and drive systemic improvements. After any significant incident (say the website crashed due to a surge in traffic or a bug in a service), conduct a blameless postmortem. Document what went wrong, why, and what can be done to prevent it in the future. Track the follow-up actions (e.g. “implement rate limiting on Service X” or “add automated failover for Database Y”) and ensure they are completed. Over time, this process greatly improves reliability because the same mistake won’t be made twice. It also fosters trust – developers and ops won’t hide issues for fear of blame, meaning you get a clear picture of problems. Many high-performing companies attribute their reliability in part to a strong postmortem culture supported by SRE, which turns incidents into opportunities to harden the system. In a complex distributed environment, this practice is invaluable: it’s how your architecture iteratively evolves to handle conditions you didn’t initially foresee.
8. Collaborate and Communicate Across Teams:
SRE’s position is inherently cross-cutting – you’ll interface with developers, product managers, support, and sometimes directly with business stakeholders. It’s important to set up regular communication channels: for example, SRE can have weekly syncs with each major product team to review any reliability concerns, upcoming launches, or required support. Participate in design reviews for new features to inject reliability considerations (maybe the new feature to add real-time order tracking should use an event stream instead of synchronous calls – those suggestions are easier to incorporate early). Also, communicate reliability status visibly – e.g. publish SLO reports that everyone in the company can see, like “last week, checkout service met 99.95% availability against a 99.9% SLO” or “we had 3 priority incidents, all related to Service Z’s database.” Transparent communication ensures reliability stays top-of-mind and creates a shared responsibility. In a retail company, for instance, the business team should know that the reason the site is so stable is because of conscious SRE efforts; this helps justify investments in reliability engineering and prevents the situation where only new features get attention at the expense of stability.
By following this strategic guide, SRE teams can lead the transformation of Operations in embracing distributed architecture. The focus is on being proactive, data-driven, and automation-oriented. In essence, SRE provides the practices and mindset to harness the power of distributed systems (microservices, distributed databases, service meshes) while keeping the system reliable and maintainable. As sources often highlight, SRE “enables organizations to confidently scale complex systems, while maintaining high availability… and cost-effectiveness.” For retail and e-commerce platforms aiming to innovate rapidly without outages or customer dissatisfaction, this blend of distributed architecture and SRE is not just advantageous – it’s becoming essential for success in the digital era.
Why Database Reliability Engineering (DBRE) is Critical
One of the hardest problems in distributed systems is the database.
In e-commerce:
- A checkout flow touches inventory DBs, payment DBs, and user DBs.
- A product search may hit caching layers, search indexes, and catalog DBs.
- Global customers demand low latency reads/writes across regions.
Challenges include:
- Distributed transactions across heterogeneous DBs.
- Replication lag and consistency issues in multi-region setups.
- Scaling databases independently of services.
- Observability gaps for DB performance (queries, locks, slowdowns).
This is why Database Reliability Engineering (DBRE) has emerged as a specialized practice. DBREs apply SRE principles to databases:
- Automating schema changes and migrations.
- Monitoring query performance and replication health.
- Designing resilient failover for databases (active-active, active-passive).
- Ensuring compliance and data integrity across regions.
Without DBRE, distributed systems can suffer data silos, inconsistencies, and outages that cripple the entire platform. With DBRE, databases evolve into reliable, observable, and scalable foundations.
Conclusion
Distributed architecture is the future of retail and e-commerce. It enables global scale, rapid innovation, and fault isolation — but it also introduces unprecedented complexity. The key to mastering this complexity is Site Reliability Engineering (SRE), which transforms operations from firefighting to engineering. SRE practices ensure that microservices, distributed databases, and service meshes remain reliable, observable, and resilient. At the heart of this transformation lies Database Reliability Engineering (DBRE), ensuring the data backbone of e-commerce is as reliable as the services built on top.
By combining distributed design + SRE principles + DBRE discipline, organizations can deliver what truly matters: fast, reliable, and trustworthy digital experiences for their customers.
Previous article